
GSOC 2017 project proposal
Ivan Josa, Universitat de Lleida (UdL) student, Spain
Fly Over Your Big Data (FlOY-BD)
My name is Ivan Josa and I am a student from Lleida (Spain). I am currently in my last
year of Master’s Degree in Computer Science specialized in Big Data Analysis.
year of Master’s Degree in Computer Science specialized in Big Data Analysis.
Previously to these studies, I have made an Engineer Degree also in the University of
Lleida, more concretely in the Polytechnic Faculty.
Lleida, more concretely in the Polytechnic Faculty.
In 2012 I achieved Java SE 7 Associate Programmer certification and in 2015 I
obtained the FCE from Cambridge English.
obtained the FCE from Cambridge English.
I have previous knowledge on Java EE environments and Linux systems management
as I have a Diploma of Higher Education specialized in Managements and
Administration of Computer Systems by UdL.
as I have a Diploma of Higher Education specialized in Managements and
Administration of Computer Systems by UdL.
Other Projects and knowledge:
GSOC 2016 Successful Participant
CoDi P2P. I worked on this project as member of the Distributed Computing
research group in UdL.
- Java EE projects using Spring, Struts, JPA, Servlets,...
- Android Knowledge
- Python Knowledge
- Hadoop & Spark Knowledge
- Drupal Management and Module Development
- Magento Management
- Liferay Management and Development
Project Description
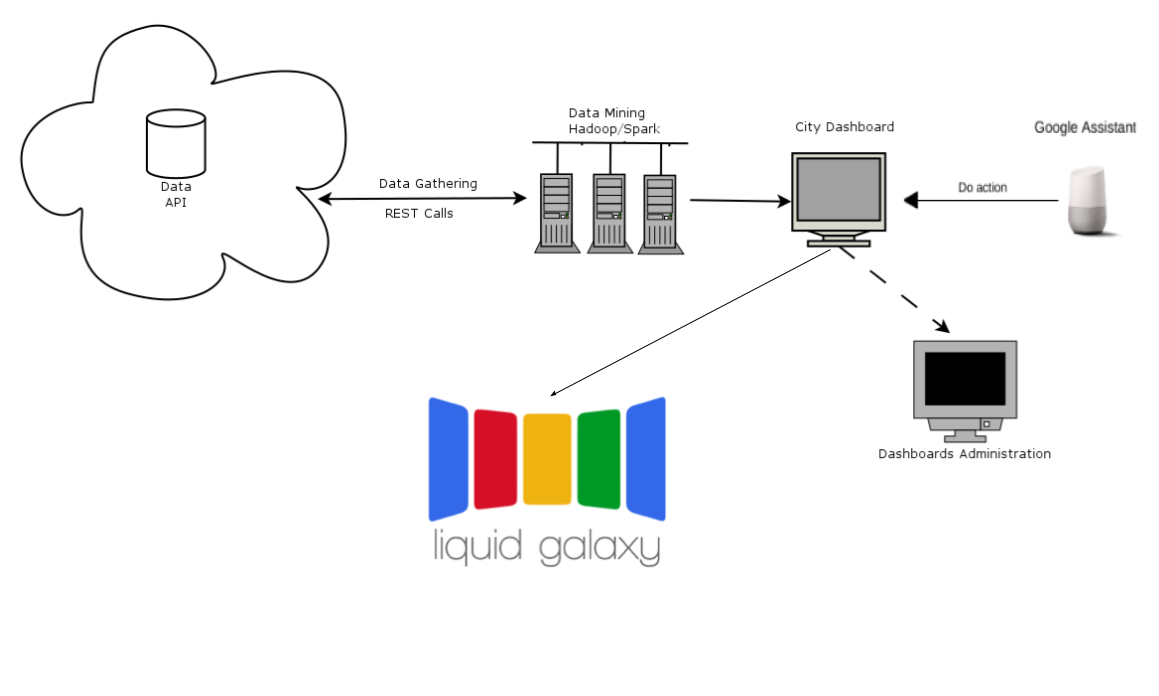
The aim this project is to develop a system that, making use of the Liquid Galaxy
capacity to display information over an interactive map, displays data (in this case
meteorological data ) obtained from a big data analytics and mining process.
capacity to display information over an interactive map, displays data (in this case
meteorological data ) obtained from a big data analytics and mining process.
Firstly, the data will be gathered from public data APIs and, after being cleaned,
stored in a Nosql database to be processed later. This information will be related to
historical weather conditions, water and energy historical reservoirs, earthquakes
and other weather related information that could come to mind during the
development of the project.
stored in a Nosql database to be processed later. This information will be related to
historical weather conditions, water and energy historical reservoirs, earthquakes
and other weather related information that could come to mind during the
development of the project.
Secondly, the data will be analysed under some kind of data analysis algorithm such
clustering with K-Means algorithm or Regression Models making use of a Spark
Uni-Node System running on the cloud and Python as programming language, more
concretely its pySpark library.
clustering with K-Means algorithm or Regression Models making use of a Spark
Uni-Node System running on the cloud and Python as programming language, more
concretely its pySpark library.
Finally, the conclusions obtained from this data analysis will be shown on a external
interface, such a website running in a server connected to the Liquid Galaxy, in a
dashboard format (for example: http://citydashboard.org/london/ ) for each of the
considered cities.
interface, such a website running in a server connected to the Liquid Galaxy, in a
dashboard format (for example: http://citydashboard.org/london/ ) for each of the
considered cities.
This dashboard (developed with the Django framework), will offer to the end-user,
the possibility to seamlessly display the chosen information into Liquid Galaxy.
Then the system will automatically send the corresponding KML files to Liquid Galaxy
in order to display this information in a descriptive and visual way, for example
percentual polygons, polylines, etc.
the possibility to seamlessly display the chosen information into Liquid Galaxy.
Then the system will automatically send the corresponding KML files to Liquid Galaxy
in order to display this information in a descriptive and visual way, for example
percentual polygons, polylines, etc.
Another data source will be the General Transit Feed Specification (GTFS) that
defines a common format for geographic information, usually about public
transportation. GTFS implements a standard used in several data platforms, that
provide great information to the citizens daily life. The idea is to capture the
information of GTFS feeds and cross it with current weather data in order to make
best route predictions.
defines a common format for geographic information, usually about public
transportation. GTFS implements a standard used in several data platforms, that
provide great information to the citizens daily life. The idea is to capture the
information of GTFS feeds and cross it with current weather data in order to make
best route predictions.
Finally, an additional functionality to the system is its integration with Google Assistant using actions
SDK and contextual capabilities to make voice requests, for instance display the current weather for a
city or calculate the best route from one city to another.
SDK and contextual capabilities to make voice requests, for instance display the current weather for a
city or calculate the best route from one city to another.
Some special questions
- The data mining will be developed through Spark technology, more concretely
through its implementation in python, called pySpark. Spark is a higher layer of
Hadoop which implements its map-reduce algorithm focused on clustering.
- In some specials cases, Hadoop could be suitable as well and therefore, the data
mining could be also done under Hadoop.
- The data displayed is tied to the available data sources and their format
- The data for each city depends on what they share
- The data mining process will be focused on obtaining value from the data,
either from the data itself or from the correlation with other data source
Use Case
- Display Actual Weather
- Display Historical Weather within a time period
- Display Historical Weather at a concrete time
- Display lines/figures representing the data
- Make a tour for different points of data:
- “Show me the temperature change of Barcelona for the last 10 years.“
- “And the last 5 years?”
- “And the precipitation?”
- Calculate the route from Lleida to Sevilla
- Google Assistant Context Management:
Linked Technologies
- RESTful calls for querying the data APIs
- Python
- for the data gathering
- for the Django web development
- for the data cleaning and mining steps via pySpark library
- HTML/CSS for the frontend development
- KML for the data visualization
- Assistant (Actions SDK, Api.AI)
- GTFS
Values for Liquid Galaxy community
- BigData Integration
- Could be used for teaching purposes
- Possibility to adapt it to Smart Cities data visualisation in a future
Timeline
Previous to GSoC (before May 4th):
- Research on Liquid Galaxy and Google Earth platforms
- Research on Smart Data Platforms
Bonding period (from May 4th to May 30, 2017):
- Prepare the development environment
- Initial Data Gathering
First Working Period (from May 30, 2017 to June 30, 2017):
- Complete Data Gathering and Cleaning
- Data Mining
Second Working Period (from July 1,2017 to July - 24, 2017):
- GTFS data search and processing
- Web frontend and backend development
Third Working Period (from July 25,2017 to August - 20, 2017):
- Link web to Liquid Galaxy and testing
- Provide Google Assistant functionality to the system.
- Documentation
Closing and Finalization (from August 21 to 29, 2017):
- Finish documentation







